Effect of acceleration in gradient descent¶
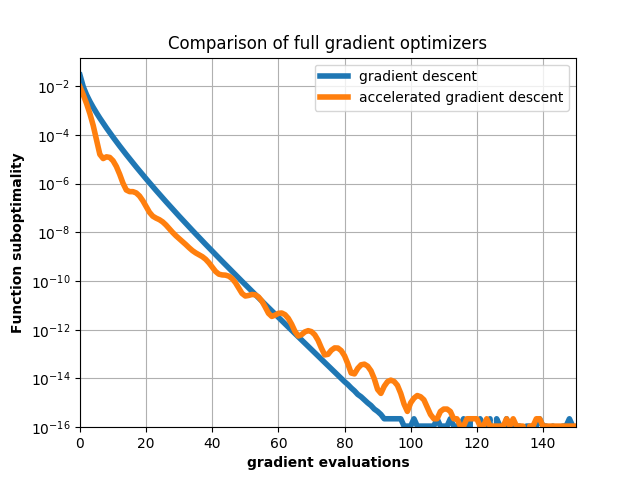
Showcase the improved convergence of accelerated gradient descent on a logistic regression problem.
import numpy as np
import pylab as plt
import copt as cp
# .. construct (random) dataset ..
n_samples, n_features = 1000, 200
np.random.seed(0)
X = np.random.randn(n_samples, n_features)
y = np.random.rand(n_samples)
logloss = cp.utils.LogLoss(X, y).func_grad
cb_pgd = cp.utils.Trace()
cb_apgd = cp.utils.Trace()
L = cp.utils.get_lipschitz(X, 'logloss')
step_size = 1. / L
result_pgd = cp.minimize_PGD(
logloss, np.zeros(n_features), step_size=step_size,
callback=cb_pgd, tol=0, line_search=False)
result_apgd = cp.minimize_APGD(
logloss, np.zeros(n_features), step_size=step_size,
callback=cb_apgd, tol=0, line_search=False)
trace_func_pgd = np.array([logloss(x)[0] for x in cb_pgd.trace_x])
trace_func_apgd = np.array([logloss(x)[0] for x in cb_apgd.trace_x])
# .. plot the result ..
fmin = min(np.min(trace_func_apgd), np.min(trace_func_pgd))
plt.title('Comparison of full gradient optimizers')
plt.plot(trace_func_pgd - fmin, lw=4,
label='gradient descent')
plt.plot(trace_func_apgd - fmin, lw=4,
label='accelerated gradient descent')
plt.ylabel('Function suboptimality', fontweight='bold')
plt.xlabel('gradient evaluations', fontweight='bold')
plt.yscale('log')
plt.ylim(ymin=1e-16)
plt.xlim((0, 150))
plt.legend()
plt.grid()
plt.show()
Total running time of the script: ( 0 minutes 2.955 seconds)
